
RAG Chatbot Platform with Custom Knowledge Bases and Multi-Language Support
Client project: a chatbot embedding platform built on a Langchain RAG pipeline, FastAPI on GCP, and Supabase. Supports custom knowledge base ingestion and 60+ languages.
Problem
The client wanted a chatbot platform that businesses could train on their own content — product docs, FAQs, support history — and embed on their website. The constraint: non-technical users needed to be able to add and update the knowledge base without engineering help.
Generic chatbot tools either don't support custom training data or require a developer to retrain a model. The goal was a middle path: a RAG pipeline where the "training" is just uploading a file or pasting a URL.
Why It's Hard
RAG retrieval quality degrades with noisy inputs. The knowledge base comes from file uploads (PDF, DOCX, TXT) and link-based web scraping. Real business content is inconsistently formatted: headers in body text, tables that don't parse cleanly, navigation links mixed into page content. Garbage in, garbage out — poor chunking and embedding quality produces hallucinated or irrelevant answers at retrieval time.
Multilingual LLM output is inconsistent. The system supports 60+ languages. The challenge isn't translation — it's that the underlying LLM occasionally slips back into English mid-response, especially for low-resource languages or when the retrieved context is in a different language than the query. Getting consistent language-matched output required explicit prompt constraints and post-processing checks.
Embedding scripts in arbitrary third-party sites. The chatbot is embedded via a JavaScript snippet in Webflow, Wix, WordPress, and custom HTML. Each platform has different CSP headers, iframe restrictions, and DOM quirks. What works in a plain HTML page breaks in Webflow. Testing across platforms was more work than the embedding code itself.
Hybrid cloud coordination. File processing (ingestion, chunking, embedding) is resource-heavy and infrequent. Chat inference is lightweight and high-frequency. Running both on the same infrastructure meant either over-provisioning for ingestion or under-provisioning for chat. The solution was separating them into independent GCP cloud functions — but that added a cross-service security boundary to manage.
Architecture
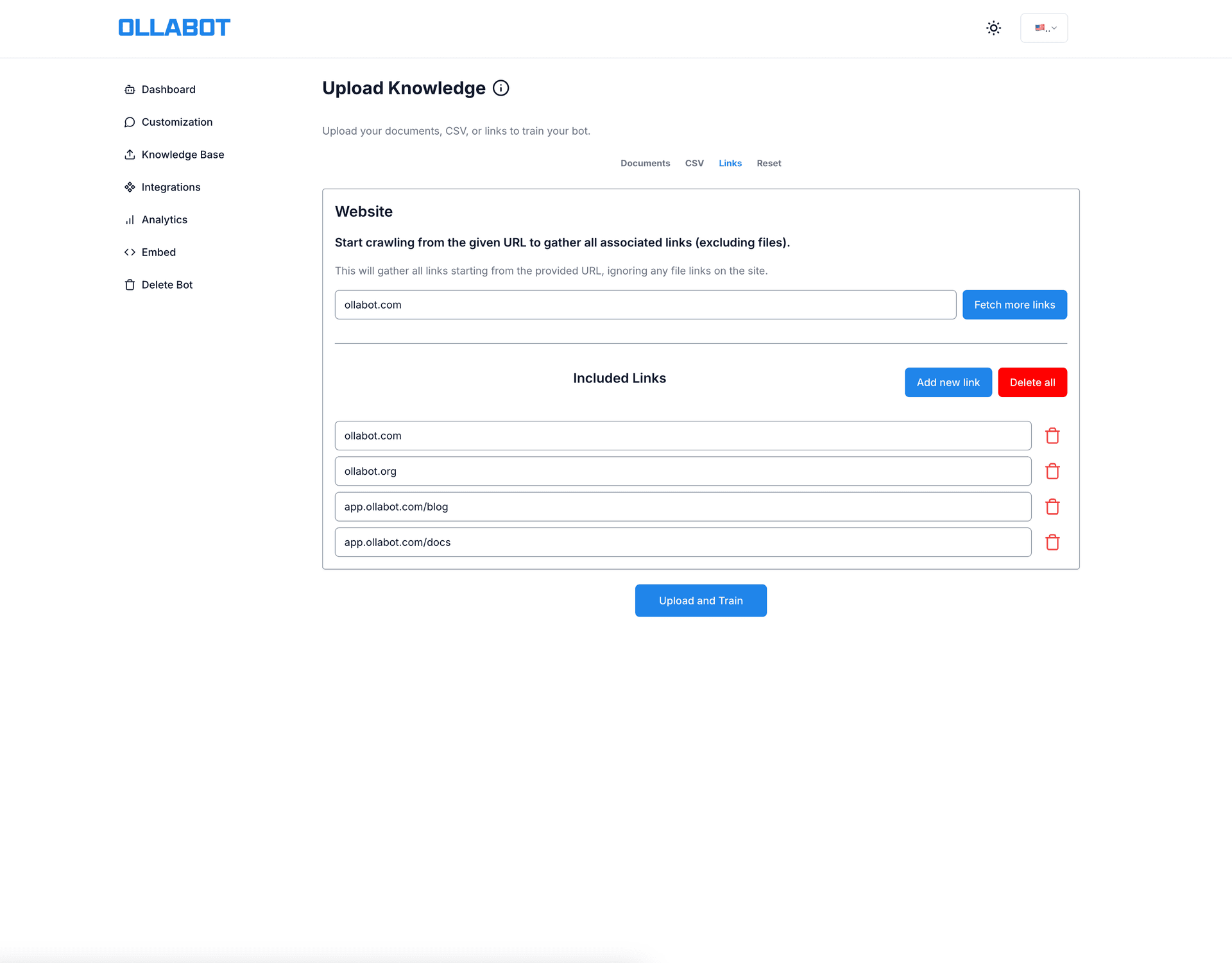
The split between Vercel and GCP was deliberate. Chat inference runs on Vercel — low latency, edge-friendly, low resource use. File ingestion runs on a GCP cloud function — higher memory, longer timeout, billed per invocation. The GCP function is locked down: API key authentication plus a VPS firewall rule that only allows requests from the Vercel frontend's IP.
The knowledge base lives in Supabase with pgvector for embedding storage and similarity search. When a user sends a message, the FastAPI backend embeds the query, runs a similarity search against the stored vectors, injects the top results as context, and sends the whole thing to the LLM with language and tone instructions.
Key Engineering Decisions
GCP for ingestion, Vercel for inference. Both could run on one platform, but the resource profiles are opposite. Ingestion needs 30s+ runtime and 512MB+ for large PDFs. Chat inference needs under 500ms cold start and minimal memory. Separate platforms, separate billing, separate scaling policies. The operational overhead of two platforms is real — but less than over-provisioning a single service.
pgvector in Supabase over a dedicated vector store. Pinecone and Weaviate were options. Using pgvector meant the vector store and the user/chat data live in the same database: same backup policy, same auth model, no cross-service joins. For a product at this scale, the operational simplicity was worth the performance ceiling.
Langchain for the RAG chain. Langchain's abstractions are heavy and sometimes opaque, but they handle the document loading, text splitting, embedding, and retrieval chain in ways that are easy to swap out. The ability to quickly swap the embedding model or the LLM without rewriting the chain mattered for a client project where requirements changed.
Language matching via prompt constraints. Rather than a translation layer, the system prompts the LLM to respond in the same language as the query. This works for common languages and degrades gracefully for rare ones (falls back to the language of the retrieved context). A proper multilingual pipeline would detect query language and translate context before injection — this was the practical tradeoff.
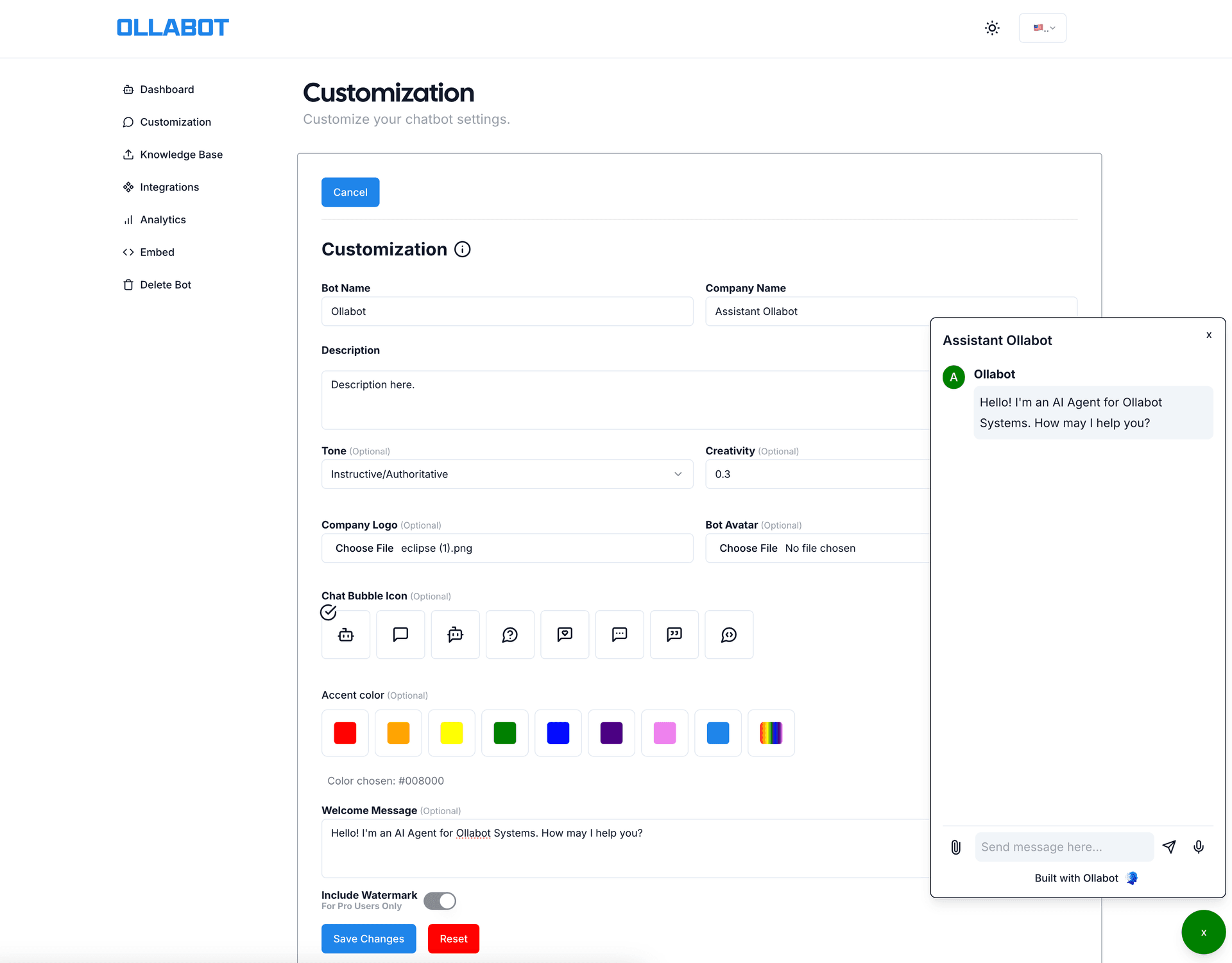
Multi-Language Support
The chatbot responds in the language of the user's query. The same knowledge base, trained on English content, can respond in 60+ languages via the LLM's multilingual capability.
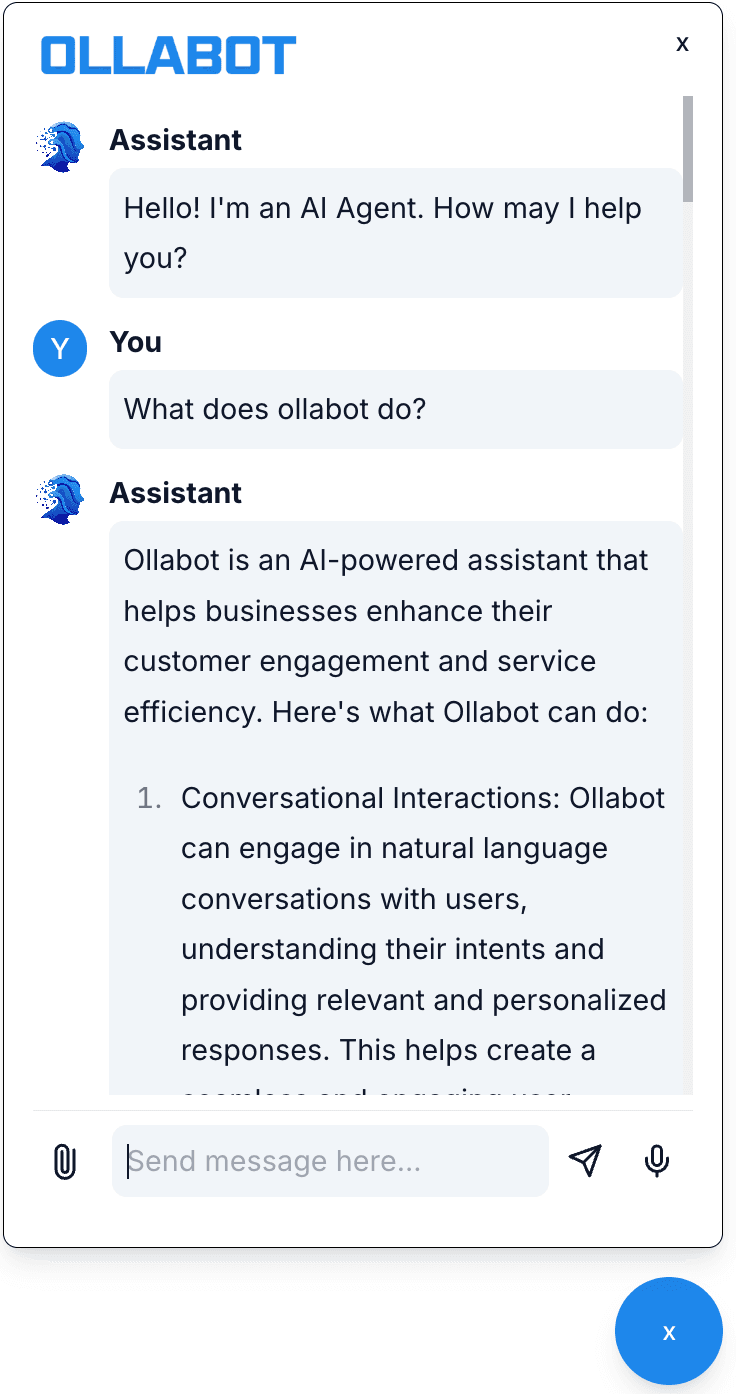
English
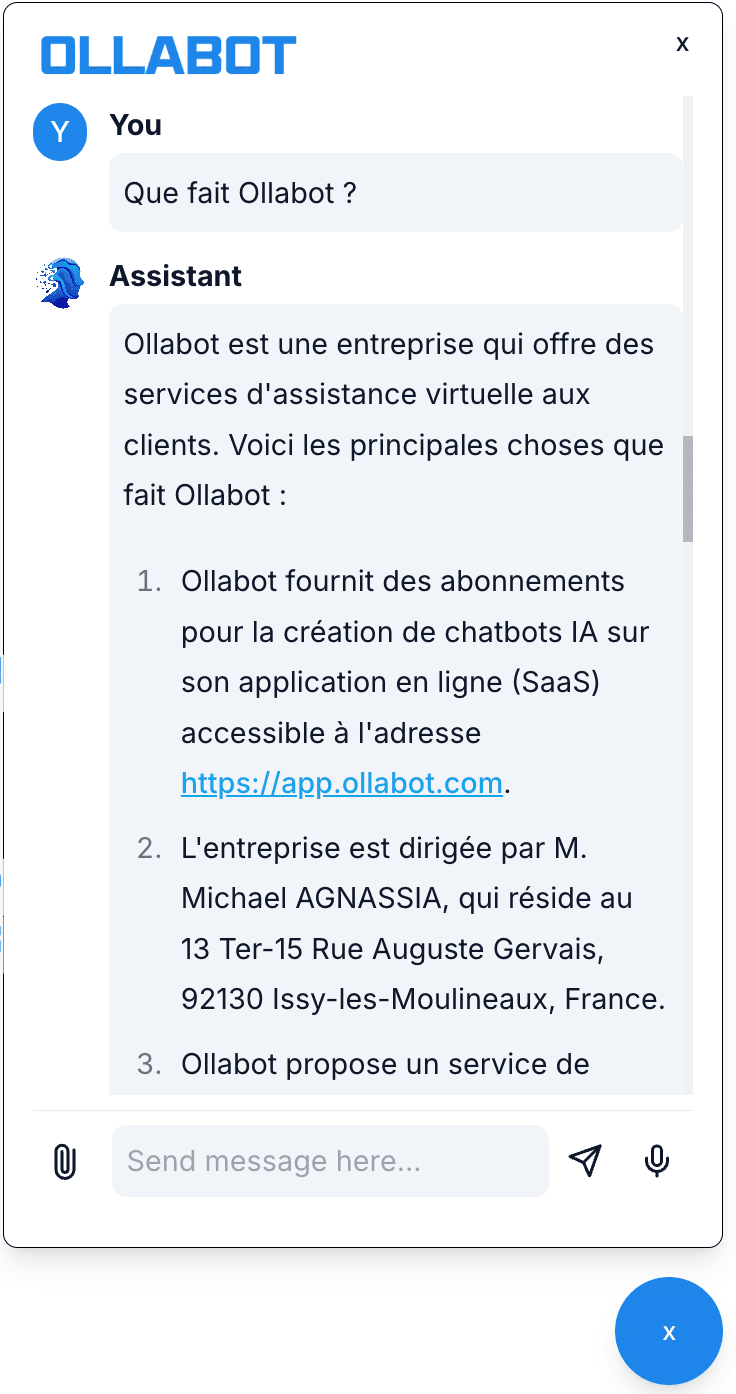
French

Spanish
What Failed
Web scraping for knowledge base ingestion is unreliable. Link-based scraping was a core feature — paste a URL, the system ingests the content. In practice, many business sites have JS-rendered content, login walls, or aggressive bot detection. Pages that worked in testing would break after a site update. I spent more time on scraper edge cases than on the RAG pipeline itself.
Chunking strategy matters more than the model. Early versions used a simple fixed-size character chunking (512 chars). Retrieved context was often mid-sentence, missing the surrounding explanation, and the LLM would hallucinate to fill gaps. Switching to semantic chunking (splitting on headers/paragraphs rather than character count) improved retrieval quality noticeably. This should have been the first experiment, not the last.
Embedding script CSP conflicts. The JavaScript embed snippet conflicted with Content Security Policy headers on several Webflow sites. The fix required client-side workarounds that varied per platform. There's no clean general solution — you're fighting each platform's security model individually.
The hybrid cloud adds debugging friction. When something breaks in production, the request might fail in the Vercel function, the GCP function, or at the IP firewall. Cross-platform tracing meant grepping two separate log systems. OpenTelemetry would have helped; we added logging manually to both sides instead.
What I'd Change
Start with semantic chunking. The document chunking strategy has an outsized impact on retrieval quality. I'd spend a day on this at the start instead of treating it as a later optimization.
Add distributed tracing from day one. The hybrid cloud setup makes debugging hard without it. A single trace ID that spans the Vercel function, the GCP function, and the database query would have saved hours of production debugging.
Test the embed script on target platforms early. The CSP issues were discovered late because testing happened on a plain HTML page. A test suite that runs the embed script against a real Webflow or WordPress install would have caught these before client handoff.
Key Lessons
RAG quality is dominated by chunking and retrieval, not the LLM. Swapping GPT-3.5 for GPT-4 on a poorly chunked knowledge base doesn't fix the hallucination problem. The retrieval layer is the bottleneck, and it deserves more engineering attention than most RAG tutorials give it.
Hybrid cloud is a legitimate architecture, but it has a real debugging tax. The resource profile argument for separating ingestion and inference is correct. The debugging cost of two log systems and two deployment pipelines is also real. Plan for both before committing.
- Supported languages
- 60+
- Platform integrations (Webflow, Wix, WP, custom)
- 4